Dataiku DSS Ver8.0 がリリースされました。
今年の3月中旬にリリースされたDataiku DSS Ver7.0から、更に機能が追加された
Dataiku DSS Ver8.0が7月中旬にリリースされました。
Dataiku DSS Ver8.0が7月中旬にリリースされました。
ちょっと調べたのですが、おそらく世界でも早い方の機能レビューではないでしょうか。
詳細については、以下のリンクを参考にしていただくとして、数回に分けてVer8.0の機能をいくつかレビューをしていきます。
DSS Ver8.0 New Features
今回は作成されたFlowを使って、簡単にビジネスユーザーが利用するシンプルなアプリケーションを作成できる、Dataiku Applicationsについて説明をします。
Dataiku Applications とは
Dataiku Applicationとは、これまで作成されてきたDSS Projectをシンプルなアプリケーションに変換できる機能です。
実際のビジネス現場で利用される場合、依頼された現場の方や実際にデータを利用したい方へ分析した結果・機械学習を使った結果を提供されるかと思います。また、新しいデータセットを使って同じモデルの結果を得たいという要望も出てくるかと思います。
そういった要望を叶えるための機能がDataiku Applications になります。
使い方としては、以下のステップで作成することが可能です。
- Dataiku Applications 化したいプロジェクトを選択
今回は、前回作成利用した、「キャンペーンに応募する顧客判定」のプロジェクトを利用します。 Flowを開いて、ツールバーにあるApplication Designerを選択します。そうすると、Dataiku Applications を設定できる画面に遷移します。
Flowを開いて、ツールバーにあるApplication Designerを選択します。そうすると、Dataiku Applications を設定できる画面に遷移します。

- 利用者に行わせたいアクションを検討し、選択
この画面で、
-「新しいデータセットを選択できる」
-「モデルの実行を行う」
-「結果をDashboardで閲覧できる」
-「アウトプットをダウンロードできる」
の4つをユーザーが利用できるようにします。
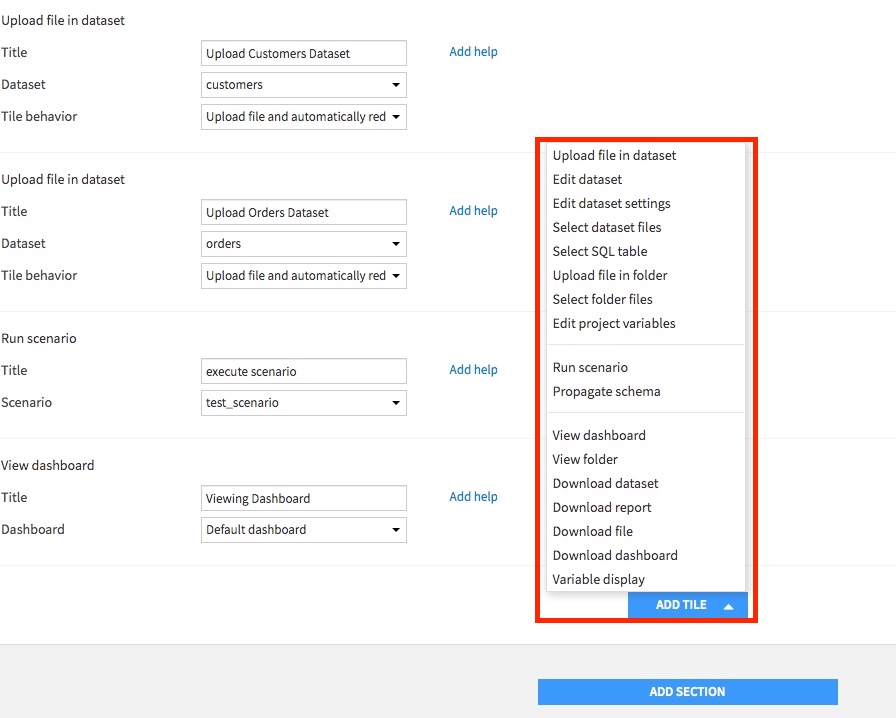
この画面の下の方に行くと、「ADD TILE」というボタンが表示されており、それを選択すると、選択できるアクションを見ることができます。
ここでは、上記アクションを行うために、以下のTILEを選択します。
-「新しいデータセットを選択できる」 → Upload file in dataset(Customer用)
→ Upload file in dataset(Orders用)
-「モデルの実行を行う」 → Run scenario
-「結果をDashboardで閲覧できる」 → View dashboard
-「アウトプットをダウンロードできる」→ Download datase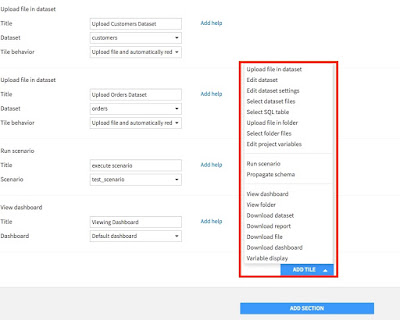 それぞれ該当のアクションと対象となるデータセットなどの指定をしますと、準備完了です。
それぞれ該当のアクションと対象となるデータセットなどの指定をしますと、準備完了です。 - Dataiku Applicationsの結果を確認。
右上にある、SAVEボタンをクリックして一度保存します。その後、その隣りにあるTESTボタンをクリックすると、以下のような画面が表示されるかと思います。 この画面のタイトルと説明はApplication Designerから自由に変更することが可能です。この画面では、先程指定した、ファイルのアップロード、シナリオの実行、Dashboardの閲覧、最終アウトプットデータのダウンロードが設置されています。
この画面のタイトルと説明はApplication Designerから自由に変更することが可能です。この画面では、先程指定した、ファイルのアップロード、シナリオの実行、Dashboardの閲覧、最終アウトプットデータのダウンロードが設置されています。
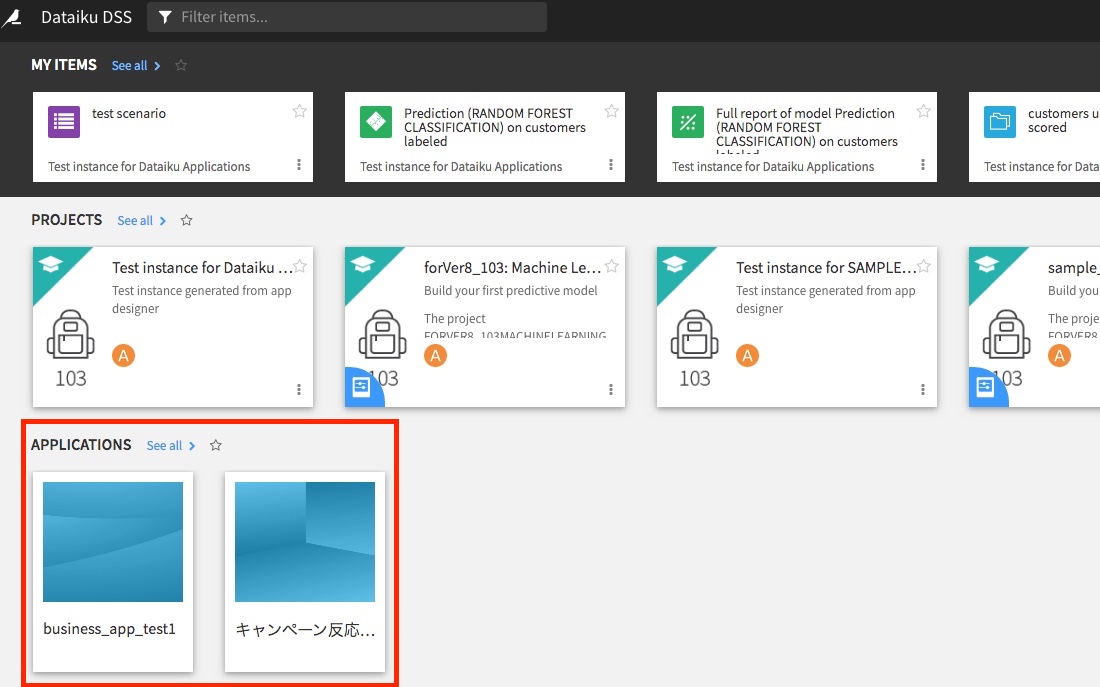
実際にユーザーへの配布については、ログインした後のトップページにApplicationsという項目ができておりますので、こちらからアクセスしてもらってください。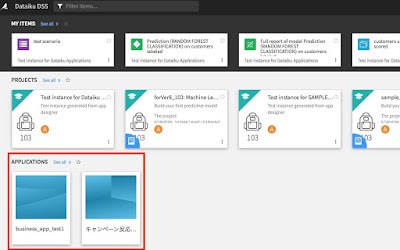




今回は、Dataiku Applicationsで実際のデータを利用するユーザーに向けてのシンプルなアプリケーションを作成する方法を紹介してみました。
実際の現場では、ユーザー側から様々な要望(データを新しくしたいので、もう一度モデルを回してみてほしい、どのようにProjectを使えばよいかわからないから教えてほしい、結果のDashboardがみたい等々…)などの問い合わせをこちらのアプリケーションを上手に設定することで、一度に解決ができるようになるかと思います。ぜひ使ってみてください。
聞くよりも実際に触ってみたほうが実感が湧くかと思いますので、ぜひ触ってみてください。フリーエディションはずっと使えて、機能的にも十分に利用することが可能です!
[フリーエディション]