今回は、「Interpretable Machine Learning = 解釈可能な機械学習」についてです。
機械学習の結果解釈
少し前までは、「機械学習はブラックボックスだ。(でも精度は良い)」という話が多く聞かれました。全体的なモデルの精度と予測はできるが、個別の結果(例えばユーザーごと)でどの変数が効いているのかを説明するのは難しい状態でした。ただ、一昨年、昨年あたりから潮目が変わってきており、こちらのドキュメントが公開されてから機械学習の結果解釈について議論が進められているようです。
Interpretable Machine Learning日本語では、Interpretable Machine Learning についてはわかりやすいかと思います。
https://christophm.github.io/interpretable-ml-book/
機械学習と解釈可能性
https://speakerdeck.com/line_developers/machine-learning-and-interpretability
Dataikuでの機械学習結果の解釈
Dataikuでの機械学習結果の解釈については、個別の対象(例:ユーザーIDや端末番号)など予測をしたい対象に対して、どのような変数が影響があったのか?というアプローチでUIを構成されています。では、実際の画面を見ていきましょう。
どこから確認するか
機械学習のモデルを作成したVisual Recipeから確認ができます。
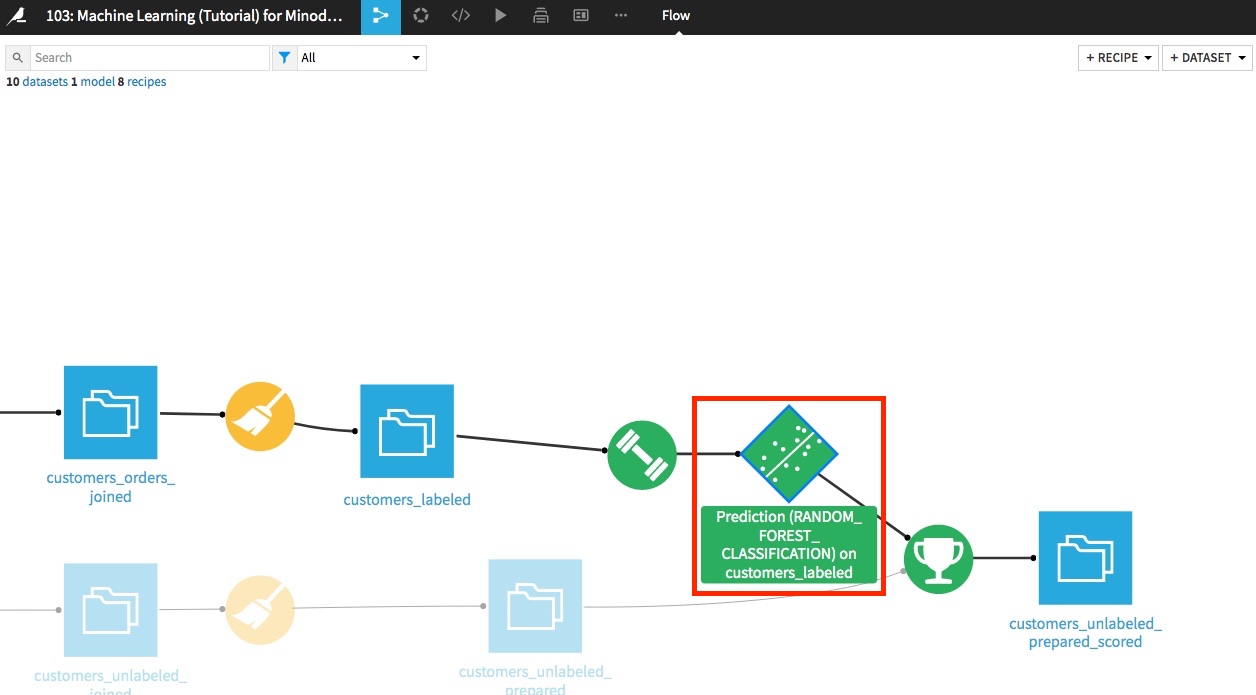

今回は一番上のRandom Forestで確認をしてみましょう。
Random Forestをクリックすると次のページに移動をしてみましょう。

左ペインのメニューの中に、「Individual Explanation」のメニューをクリックすると、上記のような画面が表示されます。初期表示だと、下の個別結果は表示されていませんが。右上にある「COMPUTE」をクリックすることで結果が表示されます。
ここでの大きな特徴は、上のグラフの両側をスライダーのように動かせ、予測確率が高いグループと少ないグループから個別の対象を抜き出すことが可能な点です。
スライダーで選択したい部分を選び、右上のCOMPUTEをクリックすると、下の画面に個別の結果が表示されます。
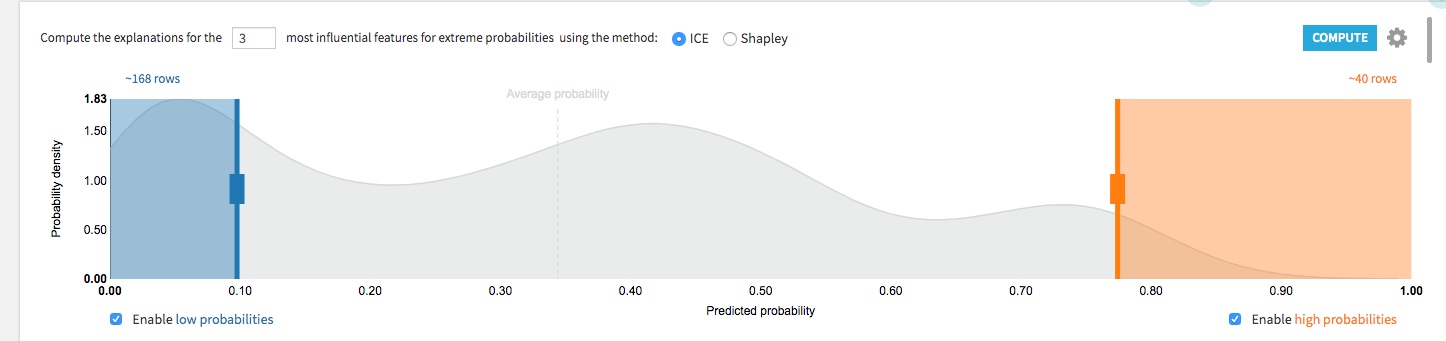
右側が予測確率が高い個別の対象で。左側が確率が低い対象になります。
(今回利用しているデータは、Eコマースの購買データを使って予測をするモデルになります。この数字は個別の顧客IDです)
以下の画面にもありますように、個別対象についてそれぞれ重要な変数を表示してくれます。
また、この対象は自由に選択することが可能です。

どのようなときに使えるか?
多くの機械学習プロジェクトでは、モデル精度を求められると思いますが、実際に現場や経営陣に説明をする際に、特定の対象(例えば特定の顧客)でどのような変数が重要だったのかを聞かれる場合もあるかと思います。
その際にこの機能を使って説明ができるかと思います。
聞くよりも実際に触ってみたほうが実感が湧くかと思いますので、ぜひ触ってみてください。フリーエディションでも十分に利用することが可能かと思います。
[フリーエディション]