これまでの内容はDataikuが標準で準備されている機能を使ってきました。
ただ、どうしても足りない機能やアルゴリズムを利用したいケースが出てきます。その場合、R(Python)を使って機能を追加させることができます。
Rのコードを実行できるだけでなく、RMarkdownやShiny、NoteBookなど近年利用が増えている機能も対応ができます。
今回はDataikuでのR言語の機能がどのように使えるのかをご紹介します。
R環境のセットアップ
RをDataikuでも利用できることはできますが、Dataikuの追加機能が多く、依存関係があるので、最初から利用できるわけではありません。環境を追加する必要があります。
R integrationこちらを見ていただき、必要に応じてAdminユーザー(管理者)に環境を準備してもらってください。R環境を作る際にAdminユーザーのコマンド(再起動とか)が必要になるためです。
https://doc.dataiku.com/dss/latest/installation/r.html
Code RecipeでRを書いてみる
では、実際にRコードを書いて見ましょう。
処理をかけたいデータセットを選択して、右ペイン中(Code Recipe)の「R」を選択してください。

その後、これまでと同様にデータセットを指定する画面が出てきます。
これまで通り、Outputのデータセット名を指定します。指定したら右下のCREATE RECIPEをクリックします。

そうすると、以下の様なコーディング画面が出てきます。

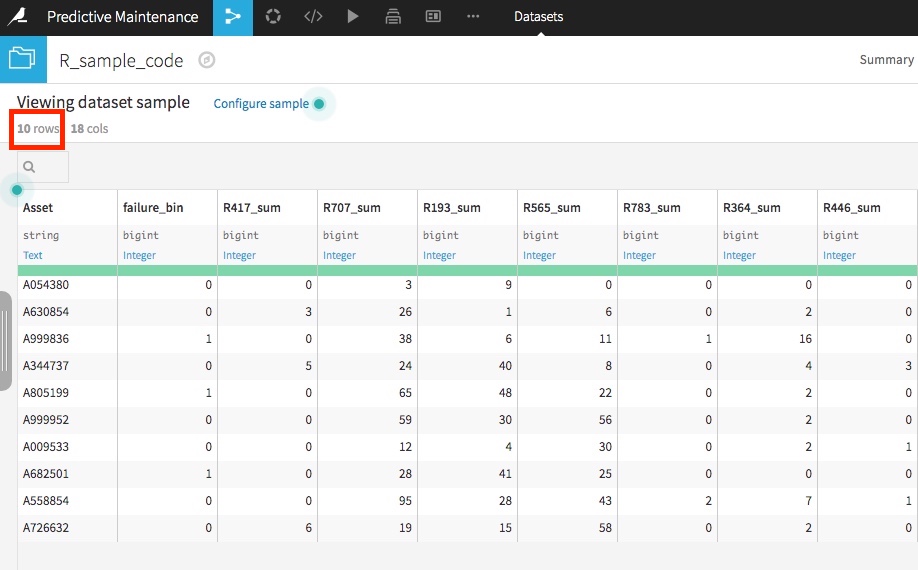
この処理は最初の10行を選択するコードを書いています。 合わせて集計パッケージのdplyrを使ってデータを処理しています。
このコードを画面下にある「RUN」をクリックして実行をすると、10行のデータが作成されます。
このように、Rコードを組み込むこともできます。ただし、Code RecipeでRコードを記載する際には、Dataiku独自のフォーマットに最初インポートする必要があります。また、Dataiku上で後続の処理にわたす際には最終的にData.Frameの形にすることが必要です。
その例として、「Rで線形回帰した結果をDataikuで再利用できるようにする」というシナリオでコードを実行してみます。
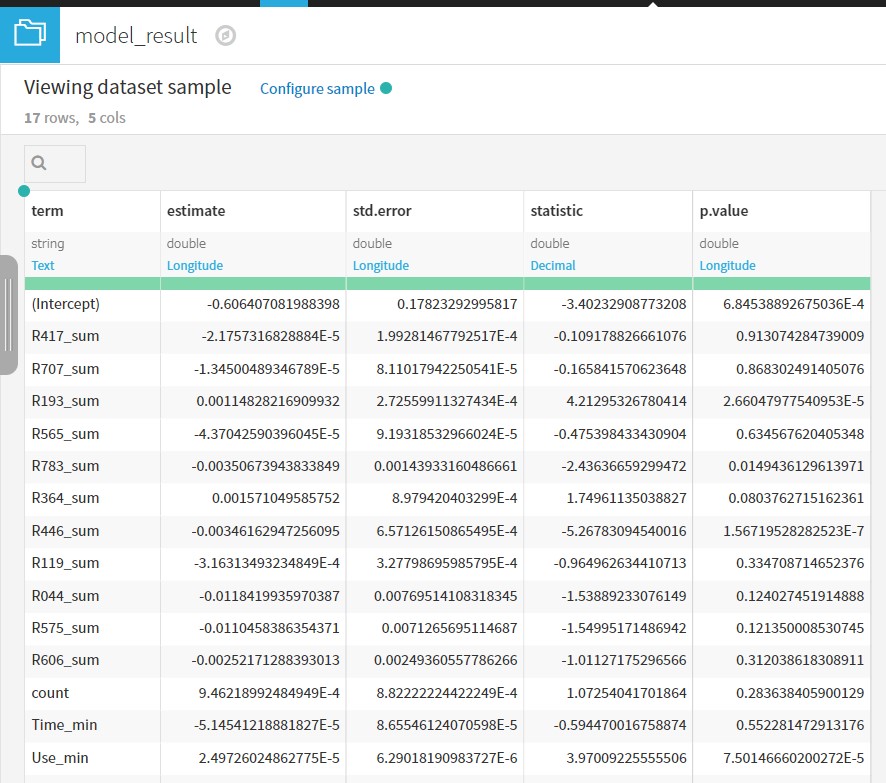
まずは以下のように線形回帰を行う関数を自実行します(lm関数)。加えて、Broomパッケージ内のTidy関数を利用して係数やp値をData.Frameに変更を行い、Dataikuで扱えるデータの形に変更をしています。

これを実行することで、Dataiku上で後続処理にこの結果データを渡すことができます。
また、サンプルコードも用意されていて、分からなくなった場合はこちらを見ながら書いてみましょう。(コードエディタの右上にあります)
内容的には、Rのdplyrを利用されたことがある方であれば、なじみ深い関数がみられるのではないかと思います。Rを使われたことがない方でもサンプルコードを見てやりたいことが記述できるはずです。

NotebookでRを書いてみる
ここまでは、Code Recipeを使ってR言語をDataikuの中に組み込んでみました。Code Recipeはあくまでも処理フローの中で利用されるため、「データ探索的」な使い方に向いていません。
そこで、DataikuではR言語が利用できるNotebookを用意しています。
分析したい対象のデータセットを選択し、右ペイン中の「LAB」をクリックします。
そうすると、以下の画面が表示されます。今回はRのNotebookを使いたいので、右ペイン中の「Code Notebooks」の中の「New」を選択してください。




これらの結果は、Flowには表示されることはなく、ツールバー内のNotebooksの中に入るので、注意してください。

また、書かれたコードは共有が可能なので、右上のPublishボタンからDashboard等へ表示させてもよいでしょう。


そこで、DataikuではR言語が利用できるNotebookを用意しています。
分析したい対象のデータセットを選択し、右ペイン中の「LAB」をクリックします。
そうすると、以下の画面が表示されます。今回はRのNotebookを使いたいので、右ペイン中の「Code Notebooks」の中の「New」を選択してください。

そうすると、Pythonはじめとして、Dataikuで利用できる他の言語が選択できますので、今回はRを選んでください。その下にどのデータセットを利用するかが聞かれます。一番上を選択してください。(フリーエディションでは、sparklyr や、SparkR は残念ながら利用できません)

右下の「CREATE」ボタンをクリックすると、以下のような画面が出てきます。
そう、これは実はJupyter Notebookです。 カーネルがRとなっていまして、R言語も利用が可能です。

RStudioと同様にパッケージをインストール、利用もできます。
今回は、dplyrを使い集計を行い、ggplot2を使った可視化を行ってみました。


また、書かれたコードは共有が可能なので、右上のPublishボタンからDashboard等へ表示させてもよいでしょう。


RMarkdownを書いてみる
続いて、DataikuではRMarkdowもサポートをしています。 PackageはRMarkdownを利用しますが、Linuxの場合はPandocが入っていないケースもあるため、その場合はサーバー管理者に伝えてPandocをインストールしてもらいましょう。
私の利用環境は AWS EC2のLinuxにインストールをしたため、Pandocが入っておらず、RMarkdownが利用できるようになるまで、セットアップに時間がかかりました。
RMarkdown Reportsインストールが完了したら、実際にやってみましょう。
https://doc.dataiku.com/dss/6.0/code-reports/rmarkdown.html
ツールバーより、RMarkdownを選択してみると、以下のような画面が表示されます。今回はこのProjectので初めてのRMarkdownになるため、「CREATE YOUR FIRST REPORT」をクリックしましょう。

次の画面では、RMarkdownのレポート名を付けます。上の選択肢は、一番上のサンプルコードを入力した状態で表示させます。終わったら、右下の「CRATE」ボタンをクリックして実行します。

次の画面では、RMarkdownのサンプルコードと共に画面が表示されます。
左ペインがRMarkdownのコード、右ペインが結果になります。
左上の「FORCE BUILD]をクリックしたら、右ペインに結果が表示されます。(下のスクリーンショットは実行した後になります)

Shinyも利用できる
Rコードの実行、Jupyter Notebookでの実行、Rmarkdownときたら、今後はShinyでしょう。
Shinyとは??と思われている方はこちらを一読ください。
Shinyとは??と思われている方はこちらを一読ください。
ゼロから作るShiny~001: Shinyってなんだ~
https://qiita.com/Anonymous1989/items/858db4ea2483d40d40ad
Shinyは簡単にいうとR言語で構築ができるWebAppで、Rの計算結果をシミュレーションできたり、地図を使ってマップ上にデータをプロットしたり等、いろいろなことが可能です。
では、DataikuではどのようにこのShinyを作れるか見ていきましょう。
まずは、ツールバー上に「WebApps」がありますので、こちらを開きましょう。
何も作成されていない場合は、以下のような画面が表示されます。「CREATE YOUR FIRST WEB APPS」をクリックしてみましょう。


次の画面では、どの言語のWebAppを作るのかを聞かれます。HTML、JS、CSSで作る、Bokeh(Python)で作る、Shiny(R)で作るかを選択できます。
今回はShinyを選択します。



スライダーを左右に動かすことで、右側のチャートの分布が変わってきます。
では、DataikuではどのようにこのShinyを作れるか見ていきましょう。
まずは、ツールバー上に「WebApps」がありますので、こちらを開きましょう。
何も作成されていない場合は、以下のような画面が表示されます。「CREATE YOUR FIRST WEB APPS」をクリックしてみましょう。

次の画面では、Web Appの名前とサンプルコードを付与するかどうかを聞かれます。今回はサンプルコードを付けておきましょう。必要に応じてサンプルコードのあり・なしを決定してみてください。
そしてWebAppの名前を入力し、右下のCREATE をクリックします。

次の画面では、どの言語のWebAppを作るのかを聞かれます。HTML、JS、CSSで作る、Bokeh(Python)で作る、Shiny(R)で作るかを選択できます。
今回はShinyを選択します。

次に以下のような画面が表示されます。左ペインにはUIとServer、右ペインには結果が表示されます。

実際に動かす際は、右ペインの「Preview」画面の中に、「START BACK END」とあるかと思います。
これをクリックすると、Shinyを起動できます。

DataikuにおけるR実行環境
DataikuでRを実行するにあたり、実行環境について注意しておく必要があります。
Dataikuでは、Python、Rともに複数の実行環境を作成することができます。
(下の画面はR‗env という環境をAdministrator > Code Env

そのため、RMarkdownやShinyなど、実行環境が異なるため「パッケージが無い」などのエラーが起こります。ですので、実際に作成したコードが動かない場合が出てきたら、Rの実行環境をチェックしてみてください。


Dataikuでは、Python、Rともに複数の実行環境を作成することができます。
(下の画面はR‗env という環境をAdministrator > Code Env

そのため、RMarkdownやShinyなど、実行環境が異なるため「パッケージが無い」などのエラーが起こります。ですので、実際に作成したコードが動かない場合が出てきたら、Rの実行環境をチェックしてみてください。
- Visual Recipeであれば Advancedタブの中にあります。

- Notebook(Jupyter Notebook)であれば、以下の画面に記載してあります。

- R Markdownであれば以下のSettings タブの画面。

- Shinyであれば、以下のSettings タブの画面。

Rパッケージのインストール
Rの最大の特徴である様々な種類のパッケージのインストール、どのようにしたらよいでしょうか?
もちろん、Rのパッケージ追加は可能です。ただし、Administrationメニューの中にあるため、一般ユーザーのみなさんは利用できないかもしれませんが、その場合は管理者に聞いてみてください。
新しいパッケージをインストール環境をAdministrator > Code Envs から選択してください。

環境をクリックすると、次のような画面が出てきます。「Requested Packages(R)」という項目があるので、そこに必要なパッケージを入力して、右ペインのUpdateをクリックします。
その際、左ペイン中の「Update all Packages」のチェックボックスは外しておくことを推奨します。Updateを押してしまうと、ほかのPackageもUpdateがかかってしまうためです。

また、現在どのようなPackageがインストールされているかを確認するのは、左ペイン中の「Actually installed packages」 ページにて確認ができます。

まとめ
今回はDataikuで利用可能な、「R言語」を使った機能の説明を行いました。
デフォルト機能ではどうしてもできない部分(複雑なデータハンドリング、最新のアルゴリズム適応)を利用したい場合にRの機能を使うことで、効率的に分析ができそうです。また、RMarkdownやShinyなど、データ探索やレポーティングでもDataikuを通して、いつものR言語が利用できるのはメリットが大きいのではないかと思います。
Dataikuは無料でしかも継続的に使えるフリーエディションや、クラウド上で準備済みの環境もあり、かつチュートリアルも充実しているので、ぜひとも一度触ってみて、実感してみてください。