前回まで
今回は機械学習の適応の続き、クラスタリングについて説明をします。
(各クラスタリングのアルゴリズムの説明はここでは行いません。別の参考資料等にてご確認ください)
クラスタリングとは
クラスタリングとは、一般的には以下のような説明がされています。
クラスタリングではデータの集合を部分集合(クラスタ)に切り分けて、それぞれの部分集合に含まれるデータが(理想的には)ある共通の特徴を持つようにする。この特徴は多くの場合、類似性や、ある定められた距離尺度に基づく近さで示される。https://ja.wikipedia.org/wiki/%E3%82%AF%E3%83%A9%E3%82%B9%E3%82%BF%E3%83%AA%E3%83%B3%E3%82%B0手元にある大量のデータが、グルーピングがされておらず、なんらかの知見を得たい場合、グループに分けることで知見が発見できる場合があります。そのような場合に、このクラスタリングは重要です。
Dataikuでのクラスタリング
では、Dataikuではどのようにクラスタリングを行うのでしょうか。
前回と同様に、以下のユースケースを用いてクラスタリングをしてみましょう。
Predictive Maintenancehttps://academy.dataiku.com/latest/usecases/L01C01/index.html
前回と同様に、
- クラスタリングをさせたいデータセットを選択
- 右ペイン中の「LAB」をクリック
- QUICK MODEL を選択 します。
そうすると、以下の画面(Choose your Task)が表示されるので「CLUSTERING」を選択します。

Clusteringを選択すると、以下の画面にうつります。ここでは、Quick Modelを選択しましょう。

次の画面では、どのようなクラスタリングを行いたいかを選択できます。ここでは、
- K-Means(一般的なクラスタリング手法)
- Interactive Clustering (一度モデルを作成した後、手動で調整ができる2段ステップ
- Anomaly detection (異常値検知)の3種類から選ぶことができます。

次の画面では、クラスタリングの設定画面となります。前回紹介した設定画面と同様に、どの変数を加えるか、どのアルゴリズムを適応するかなどを設定することができます。
今回は主だった設定項目を紹介します。
General Settings では、学習データセットのデータをどのようにサンプリングするかを指定できます。サンプリング以外でもすべてのデータを使うことも選択できます。

Feature Handlingでは、クラスタリングの学習に必要な変数をON、OFFできます。
ここでも選択した変数の内容を右ペインで確認することができます。欠損地の扱いや、この項目に含まれる値がどのような分布になっているかを一目で確認をすることができます。

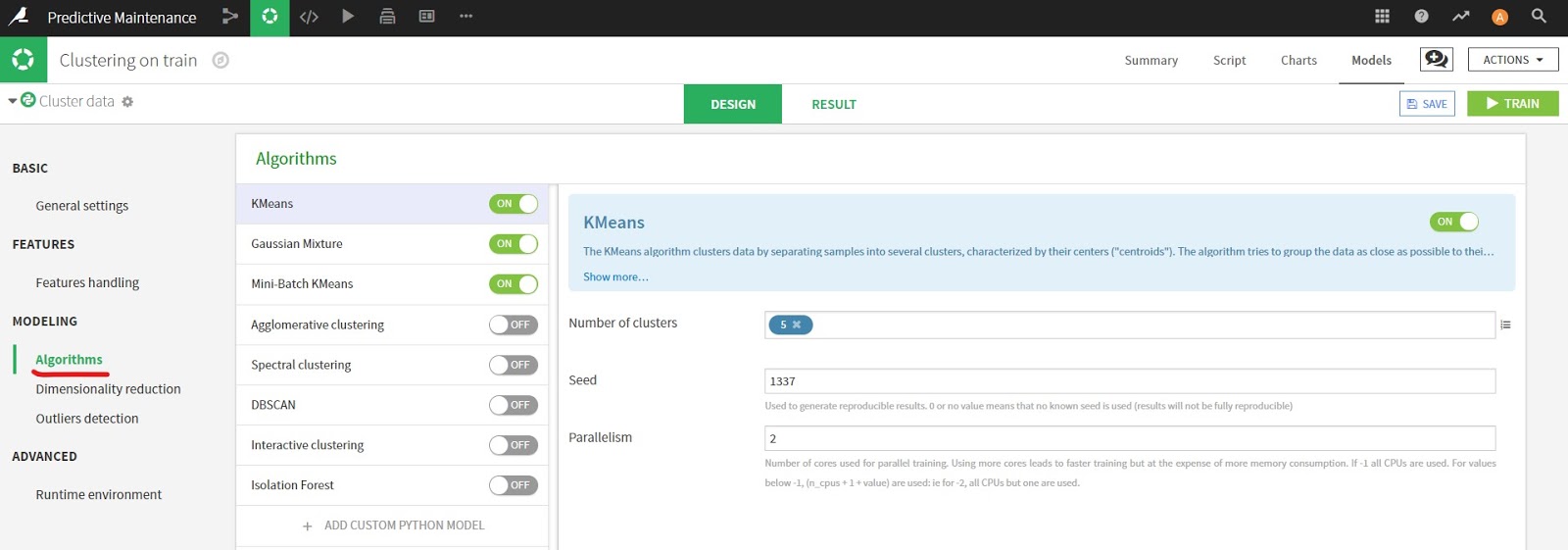
Algorithm の部分では、クラスタリングに関連するアルゴリズムを選択できます。前回のPredictionと同様に、適応させたいアルゴリズムをONにするだけで適応してくれます。また固有のパラメータも設定することが可能で、個々のアルゴリズムをカスタマイズして適応をさせられます。
続いては、Dimensionality reduction (次元削減)です。 ここでは、PCAを元にした次元削減を行うか、行わないか、両方とも試してみるか?の3択を選択することができます。

最後は、Outlier Detection (外れ値をどのように扱うか)を選択できる画面です。
Dataikuでは外れ値を検出できるのですが、それをどのように扱うか、データから落とすか、外れ値用のクラスタを作成するか、外れ値を検出しないかを選択することができます。必要に応じて設定してみてください。

では、実際に実行をしてみましょう。
実際に複数のアルゴリズムが実行がされている様子が確認できるように動画にしてみました。
以下の4点のアクションが含まれています。
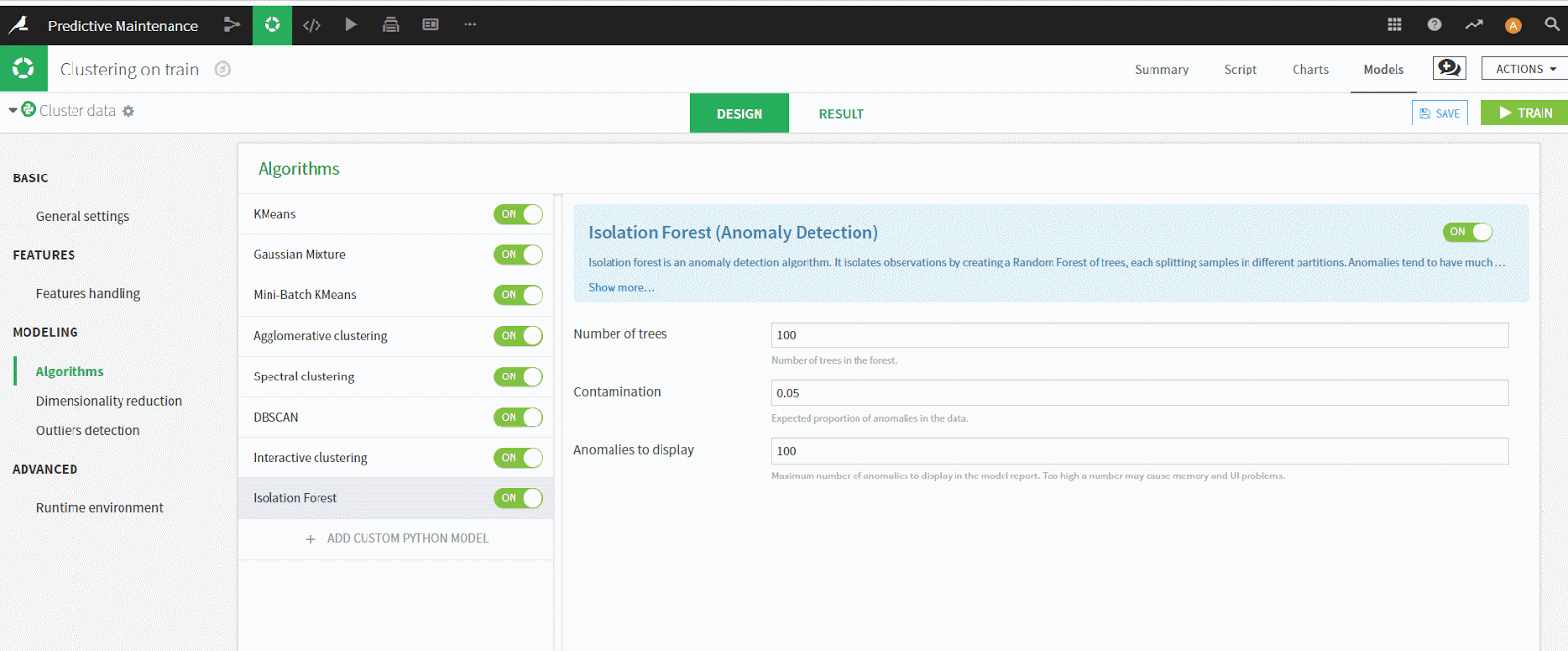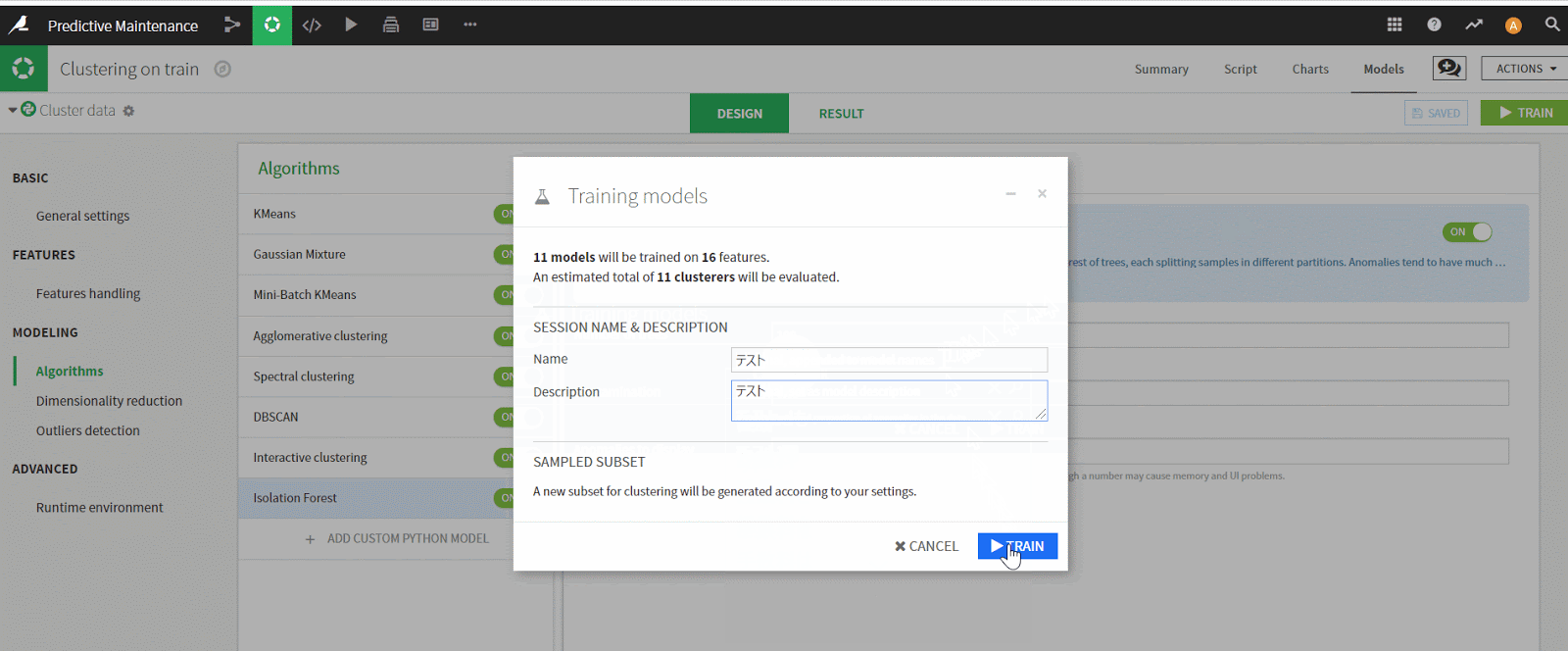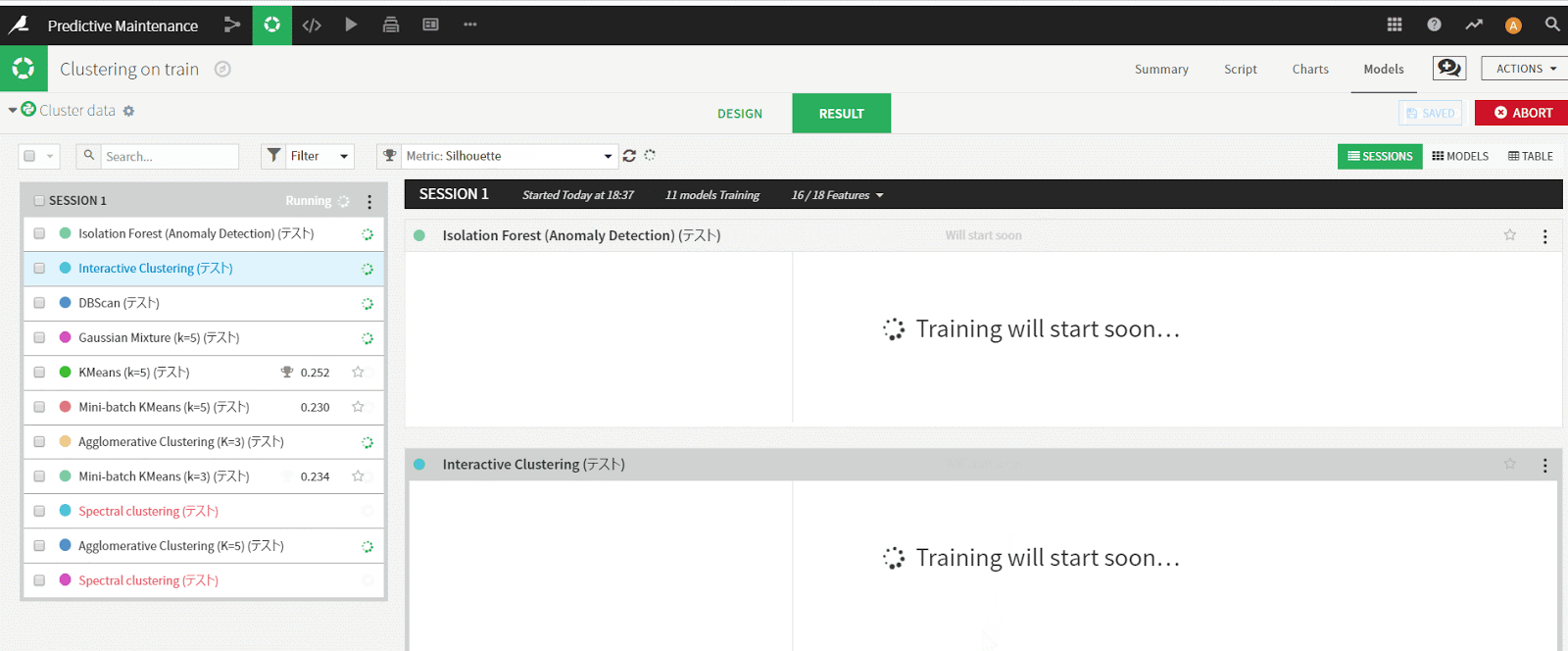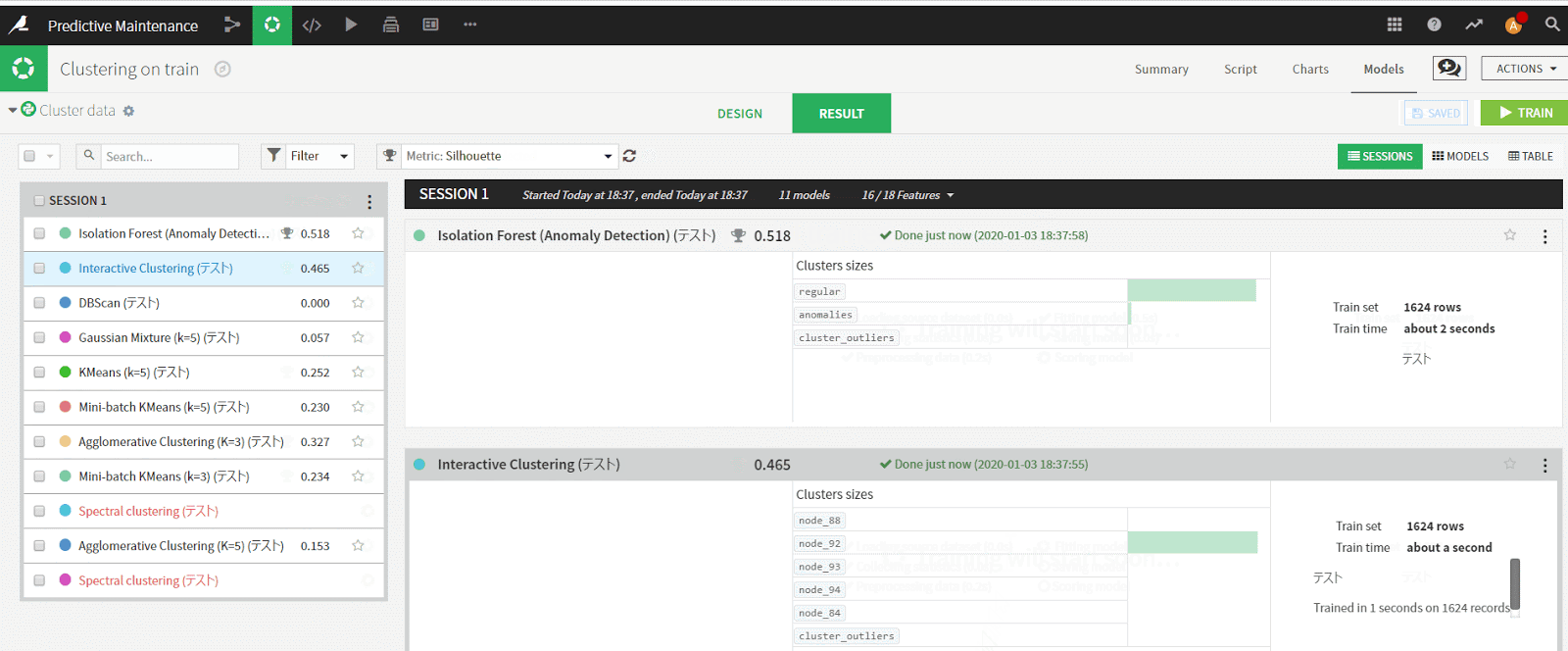
- 複数のモデルを選択
- 右上のDeploy ボタンをクリック
- 後で区別ができるように名前を入力し、実行
- 各アルゴリズムが実行される
アルゴリズムの実行が終わると、Predictionと同様に結果を見ることができます。
今回は、K-means アルゴリズムの結果を見てみます。
Summaryでは、投入したデータがどのように分類してくれたのかを確認できます。ここではクラスタの名称やその説明を入力することができます。右上にChartsがあり、この結果を使ってグラフを作成することができるので、分類された内容を様々な角度から見ながら名称を決定していけばよいかと思います。

次にValuable Importance です。 どの変数がクラスタを決定づけるのに重要だったのかを知ることができます。

Heatmapでは、各変数がどのクラスタにどのぐらい影響を与えているかがヒートマップの形で表現されています。

Cluster Profileでは、各クラスタの変数の分布が表示されます。

Scatter Plotでは、縦軸・横軸を分析した変数を指定することができ、Clusterがどのように分布しているのかが分かります。以下のチャートでは、count変数が一番聞いていることがImportanceから分かっており、それをX軸、Y軸にDistanceを置いて散布図を作成しています。散布図の点にClusterの色を配置しているため、どのようにClusterが分布しているのかが一目でわかります。

Detailed Metricsは、今回用いた評価用のスコアを表示します。(今回はSilhouetteを使いました)

このように、K-meansだけでも多くのアウトプットを表示しており、アルゴリズムの実行結果の解釈に大いに役に立つのではないかと考えられます。K-means以外のアルゴリズムも同様な結果を表示しています。(これ以外でもModel Informationとして数種類結果が表示されています)
これ以後は前回のPredictionと同様に、各アルゴリズムをクリックして、右上のDeployをクリックすると、選択されたアルゴリズムをスコアリングに利用できるようになります。
選択したクラスタリングの結果を使って、スコアリングした結果が以下の赤枠部分になります。

まとめ
今回はDataikuの機能であるAutoMLを使ったクラスタリングを行ってみました。前回と同様に画面は多くありそうですが、実際の操作はとても簡単になっており、コードを書くことよりも結果の解釈に集中ができるようになっています。Dataikuを使うことでデータアナリスト・データサイエンティストはコーディングからある程度は解放され、分析の生産性は高まるのではないでしょうか。
Dataikuは無料でしかも継続的に使えるフリーエディションや、準備済みの環境もあり、かつチュートリアルも充実しているので、ぜひとも一度触ってみて、実感してみてください。
0 件のコメント:
コメントを投稿