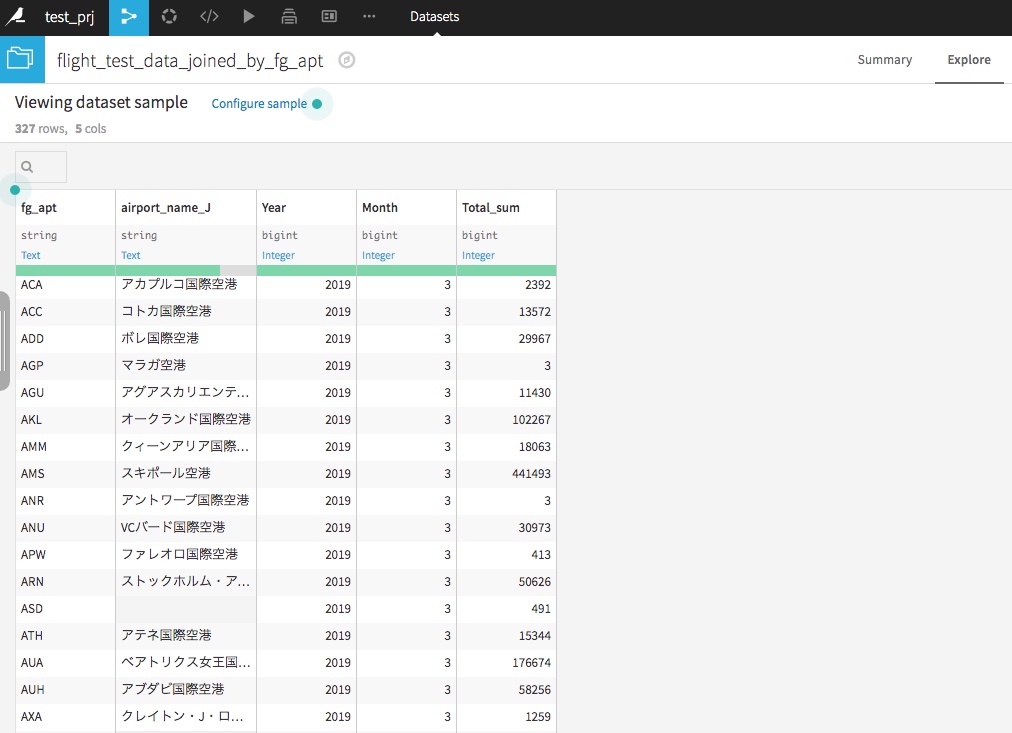
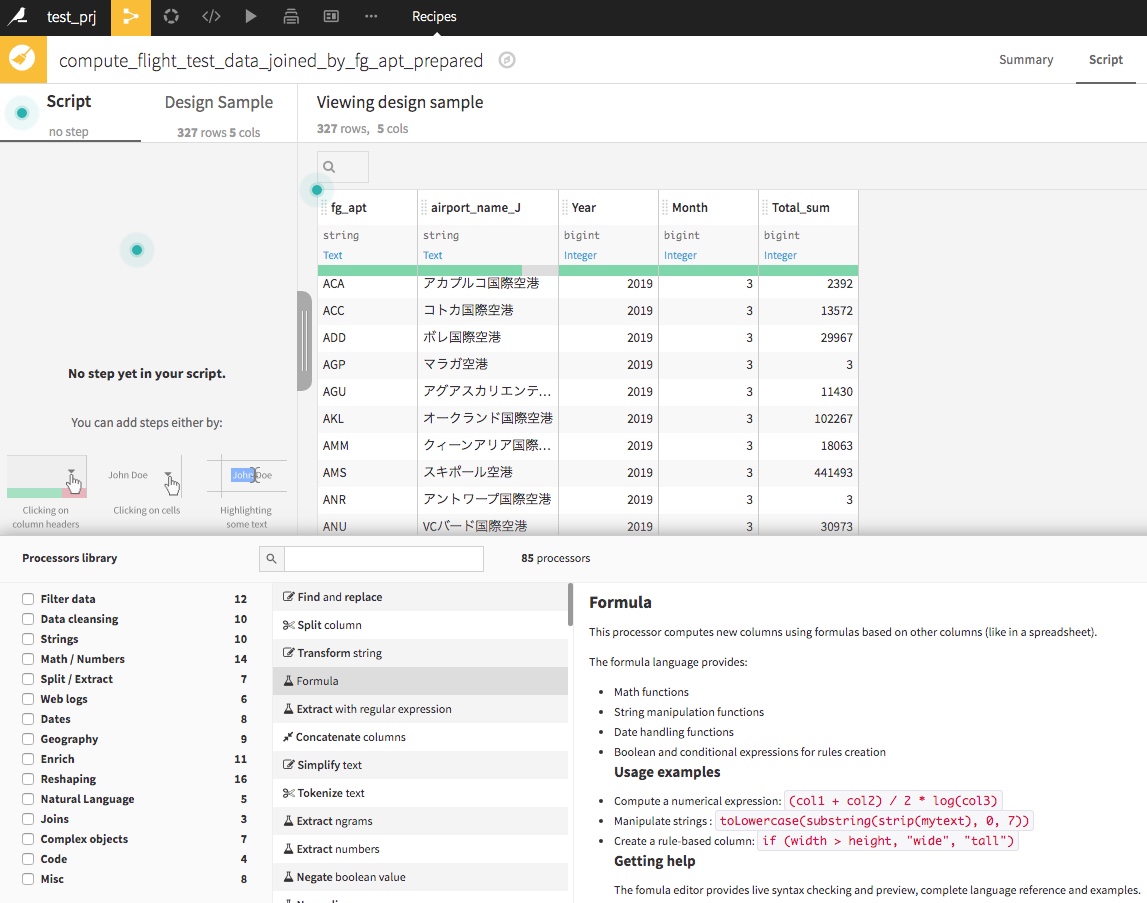
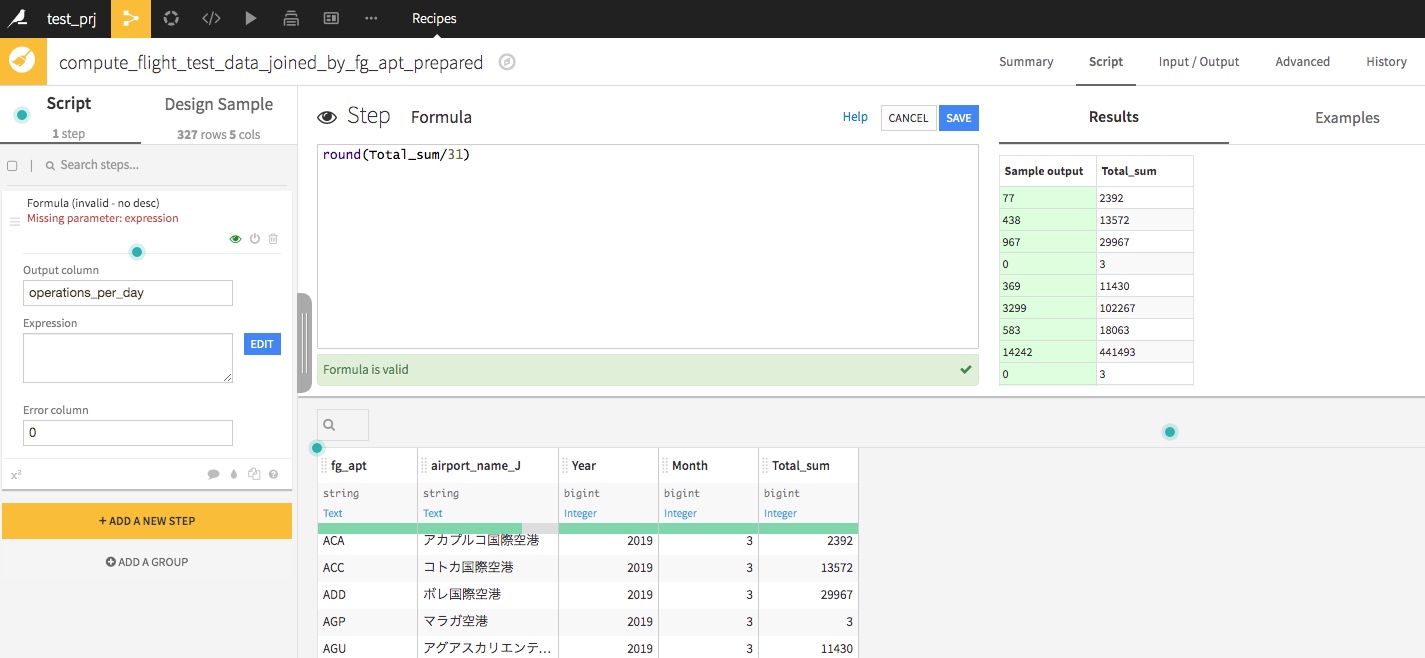
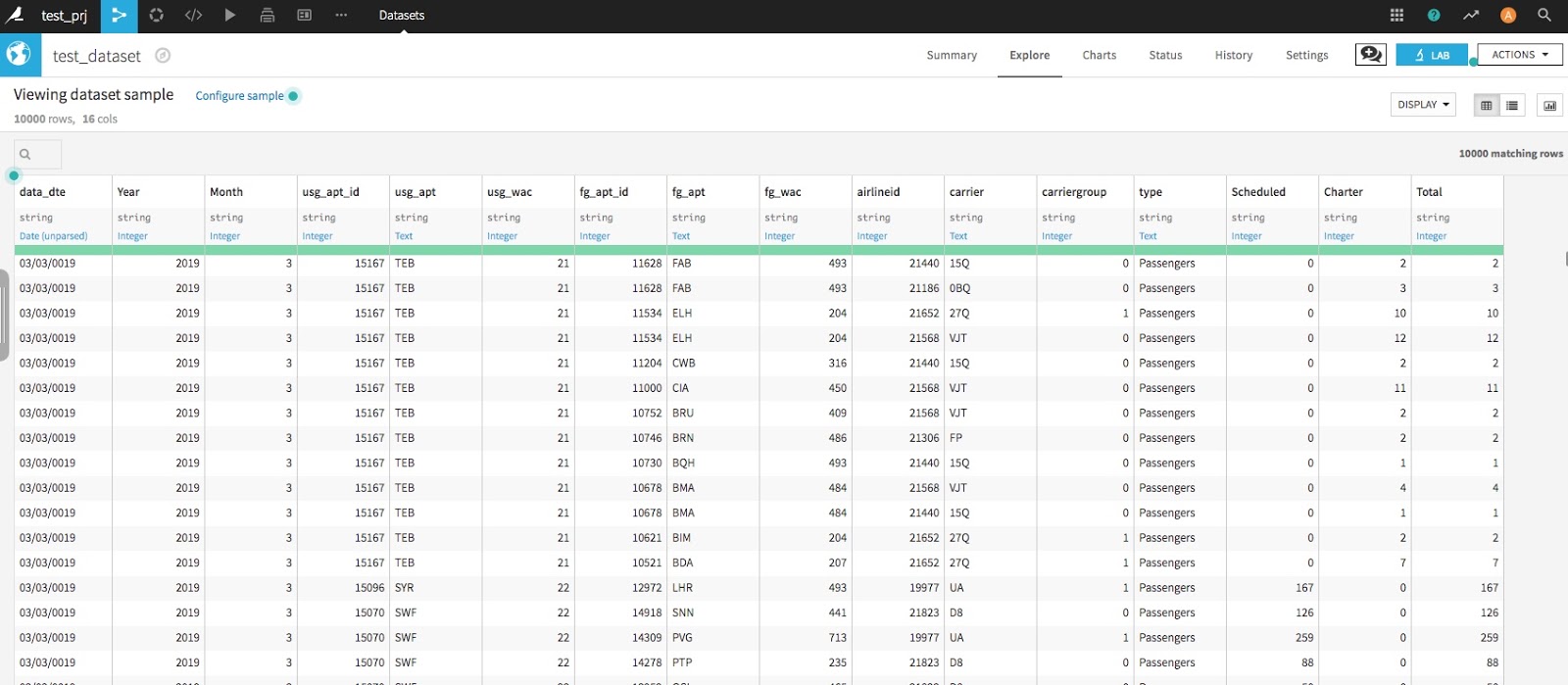
機械学習でモデルを作成する際に、データを分割して教師用データ、テスト用データに分割することがあります。また、何かしらのフラグや数値でデータを分割する場合もあるかもしれません。
その際に役に立つのが、Visual Recipeの中のSplit Recipeです。
データをランダムに比率で分割する
あるデータセットの行をランダムにセレクトしたい場合がある場合は、以下のように設定を行います。

分割したいアイコンをクリックして右枠(Visual Recipe)の中のSplit(赤枠)を選択します。
すると、以下のような画面が表示され、フォルダ名を指定することができます。ここでは、ランダムに分割をした 「Train」と「Test」 というフォルダを作っておきます。

右下のCREATE RECIPEをクリックしたら、どのような分割をするかを指定できます。今回はランダムにデータを分割させたいので、「Randomly dispatch data」 を選択します。

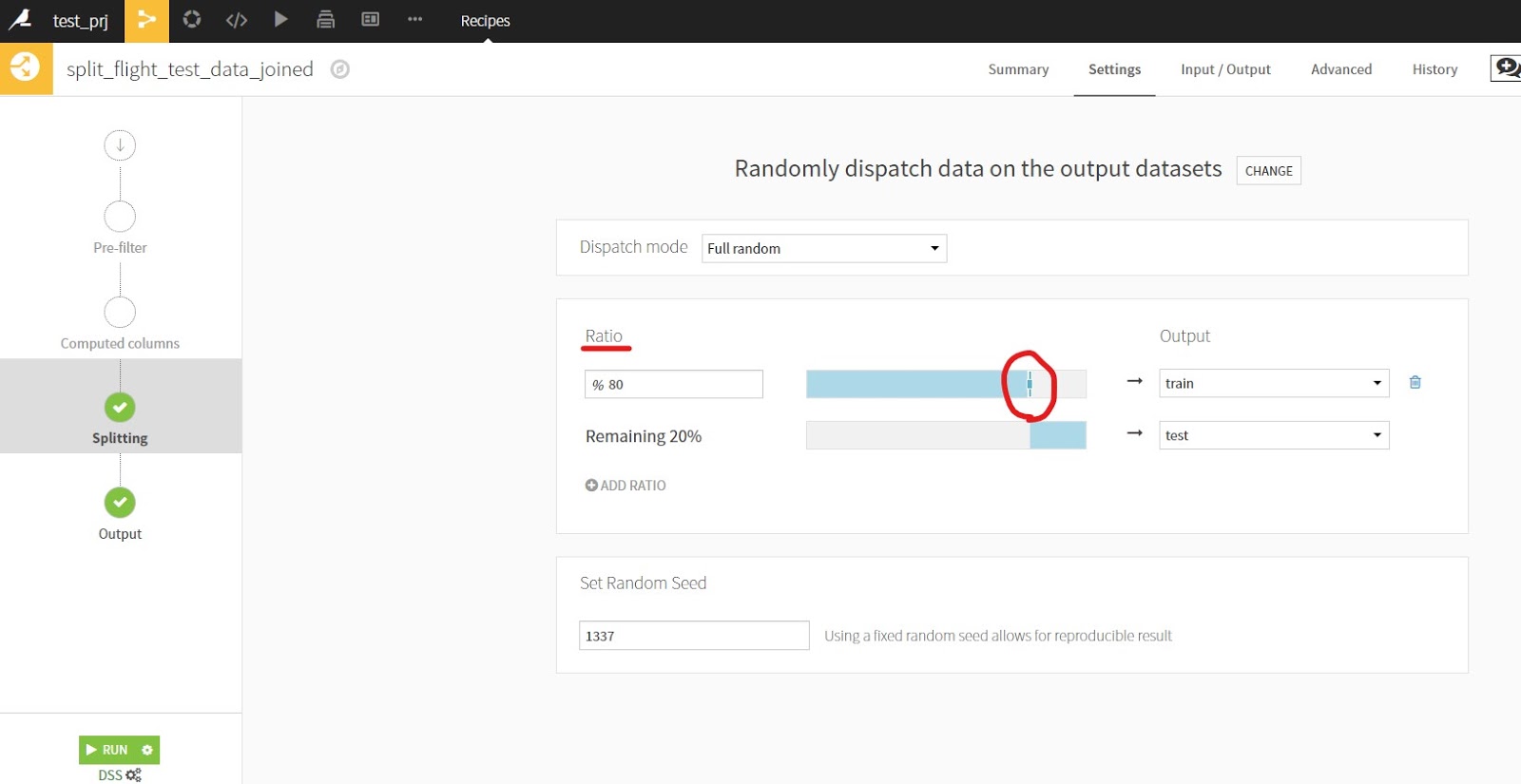
この後の画面では、実際にデータの分割割合を指定するのですが、スライダーで指定することができます。
今回はTrainに80%、Testに20%を指定します。
もちろん50%、25%、25%という風に複数指定することもできます。 「Add Ratio+」 というテキストをクリックすると、指定することができます。新しくデータセットを「Add Dataset」 から入力することも可能です。
また、Seed値を指定することが可能です。任意の値を指定できますが、変更してしまうと再度実行をした際に同様の結果が得られなくなるので、変更する際には十分気を付けてください。
指定が終わったら、左下にある「Run」を実行すると、データ分割を実行してくれます。
完了すると、以下のようにFlow上に表示されます。(赤枠が追加された部分)

データの中身を確認してみます。
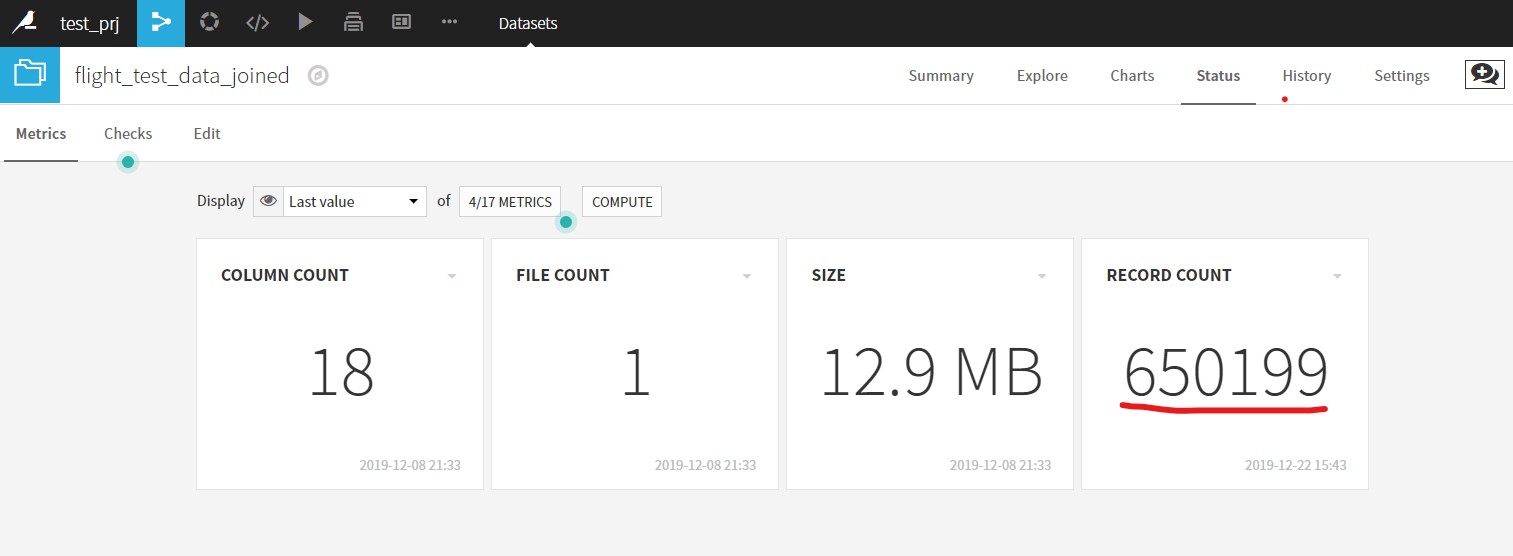
まずは元データを確認すると、650,199 行データが存在をしています。
(この表は、データセットを開いたときにツールメニューの中にある「Status」をクリックすると確認ができます。表示できていない場合は、「COMPUTE」 ボタンをクリックして更新してみて下さい)
次に、Train(80%の行数が格納されているはず)を確認してみます。
Trainデータセットを開いて同様の「Status」メニューを開いてみると、以下の結果が表示されます。
520,160 行となっていて、650,199 x 80% とほぼ同数となっています(小数点は切り上げになっているようです)

続いて、Test側を見てみます。
同様に「Status」メニューを表示してみると、130,039 となっています。
650,199 x 20% とほぼ同数となっています(小数点は切り上げになっているようです)
これで、データセットを80%:20%で分割ができていることが確認できました。
データを指定した値とそれ以外で分割する
ランダムにデータセットを分割するだけでなく、ある特定の列の値を参照して分割することも可能です。
Split Recipeを選択した後、”Map value of a single value” を選択すると、2番目の画面のように列の値を指定することができます。

Split Recipeを選択した後、”Map value of a single value” を選択すると、2番目の画面のように列の値を指定することができます。


値を指定した後、左下にある「Run」をクリックすることでデータ分割が実行されます。
Split Recipeを選択し、Define Filterを選択します。


フィルタを適応する条件(保持する行の条件)を選択することができます。
また、その下で、列を指定し値を条件で指定することができます。
数値条件であれば、>=、<=など、またテキストであればEqual (=)や文字列の一部を含む(Contains)などです。条件は複数指定することができ、それを一つのデータセットに振り分けることができます。
もちろん、違う条件で異なるデータセットに入れることもできます。(下の Add Filterで条件を追加できます)
それ以外の条件も別のデータセットに入れることが可能です。



Dataikuを学ぶには触ってみるのが一番手っ取り早いです。以下のフリーエディション(今のところ日数制限はありません)を手元のマシンにインストールして使ってみてください。
サンプルやチュートリアルが充実しているので、一度チュートリアルを通してDataikuのオペレーションを慣れると分析用にコーディングする手間が大幅に減ることは間違いないです。
閾値を指定してデータを分割する
これまでは、ランダムまたは具体的な値を指定してデータを分割してきました。ここでは、閾値を設定してデータを分割します。Split Recipeを選択し、Define Filterを選択します。


また、その下で、列を指定し値を条件で指定することができます。
数値条件であれば、>=、<=など、またテキストであればEqual (=)や文字列の一部を含む(Contains)などです。条件は複数指定することができ、それを一つのデータセットに振り分けることができます。
もちろん、違う条件で異なるデータセットに入れることもできます。(下の Add Filterで条件を追加できます)
それ以外の条件も別のデータセットに入れることが可能です。

条件の指定が終われば、いつものように左下のRunをクリックしてデータ分割を実行します。
指定した項目をソートし、割合でデータを分割する
指定したカラムでソート(昇順・降順)をして、割合で分割することができます。
売上TOP10、20%をそれぞれ別のデータセットに保存するということもできます。
Split Recipeを選択し、Dispatch percentiles of sorted data on output datasets を選択します。

次の画面では、列を指定し、その横の昇順・降順アイコン(Ascending、Descending)を選択します。下のスライドバーで割合を指定してアウトプットのデータセットを指定します。
その後いつも通りに左下のRUNアイコンをクリックすると、データが分割されます。

まとめ
今回は、Dataiku上のSplit Recipeを使ってデータ分割を紹介しました。Split Recipeでは4種類のデータ分割方法を選択することができます。
- ランダムに行を選択
- 値を指定して選択
- 閾値を指定して選択
- 指定した値をソートして割合で選択
の4つを紹介しました。
データ分析をする際に必要なデータ分割方法はカバーされているかと思います。
Dataikuを学ぶには触ってみるのが一番手っ取り早いです。以下のフリーエディション(今のところ日数制限はありません)を手元のマシンにインストールして使ってみてください。
サンプルやチュートリアルが充実しているので、一度チュートリアルを通してDataikuのオペレーションを慣れると分析用にコーディングする手間が大幅に減ることは間違いないです。
[フリーエディション]