
近年のデータアナリスト・データサイエンティスト ブームで、この職種が何をやっているのかが世の中に認知されはじめているようです。
- データハンドリング:機械学習へ適応させやすくするための加工
- データモデリング:データを何らかのモデルに適応させ、結果を取得する
- 結果の判定・シェア:どのモデルが良かったのかの判定と、関係者への説明
等々
その解決策を行ってくれるソフトウェアがありました。古くは SAS Enterprise Miner、
最近だと、KNIME、Alteryx 等が出てきました。
今回紹介するのは、その中でも昨年末におよそ1億ドル(約100億円)単位で調達を行い、いま最も注目されているデータ分析ツールの Dataiku をご紹介します。
Dataikuとは
Dataikuとは、上記のようにデータアナリスト・データサイエンティストの業務を解決してくれるソフトウェアです。クラウド上のソフトウェアではなく、クライアントPC(Mac,Windows)でも動作をしてくれます。
 詳しくはこちらのコンセプトはこちら。
https://www.dataiku.com/dss/index.html
詳しくはこちらのコンセプトはこちら。
https://www.dataiku.com/dss/index.html
基本的なコンセプトとしては、データ分析のコラボレーションが可能なコンセプトで、作られていて、データエンジニアやデータアナリスト、データサイエンティスト、はたまたマーケティングの人が同じ環境を利用してそれぞれの仕事をできるという点が大きな特徴です。
しかも、ほとんどの内容をマウス一つでできる環境になっていて、PythonやR、SQLを知らない方でも利用できるのも大きな特徴です。
基本的なコンセプトとしては、データ分析のコラボレーションが可能なコンセプトで、作られていて、データエンジニアやデータアナリスト、データサイエンティスト、はたまたマーケティングの人が同じ環境を利用してそれぞれの仕事をできるという点が大きな特徴です。
Editionと利用環境
Dataikuは期限つきのフリーではなく、「完全にフリー(一部制限機能付き)」のソフトウェアをダウンロードできます。
私はこのEditionをAWSのEC2上に構築をしています。
個人的にはEC2の t3a.xlarge を使っています。当初はAWSのフリー枠を使って見たのですが、1GBのメモリだと正しく動作しないようです。推奨は16GBのメモリーが必要とのことです。[Q&A]
https://answers.dataiku.com/4662/error-on-new-uploaded-data-files-datasets
[System Requirements]
https://doc.dataiku.com/dss/latest/installation/requirements.html
個人的に感じたとても良かった点
フリーエディションを使ってみて、以下の点についてはとても気に入っています。
- 多種多様なデータソースへの接続
Traditionalなデータソース(Oracle,Teradata,Vertica等)だけでなく、AWS S3 やHadoop、Hiveなどモダンなデータソースへの接続もできます。
* フリーエディションでは一部接続ができないデータソースもあります。
- データハンドリングのしやすさ
データアナリスト・データサイエンティストの方が直面する「データハンドリング」。データを結合したり、欠損値を補完したり、計算した結果を新たなカラムに作り出したり、縦横変換したり… と多くのことを従来であればコードベースで行う必要がありました。
Dataikuでは「Visual recipe」という機能を使うことでデータ加工が簡単に行えます。データの分割(Train、Test)、データの結合、縦横変換、変数の加工(欠損値加工や関数の適応、Geocoding、Window関数) 等々 データハンドリングに必要なものはほとんど揃っています。コードを書かずともこれらの操作ができるのはデータ加工業務を大幅に短縮できそうです。
- カラム中のデータ分布が見やすい
データ分析を始める前にデータ加工の一貫で実際のデータの中身の分布がどのようになっているかを調べるかと思います。従来であればスクリプトで確認をして変更をして…という調査と変更を行う必要があるのですが、Dataikuの Analyze 機能を使うことにより、一発で項目に何が入っているかを把握することができます。
また、上記のVishal recipeを使うことで値を変更することも可能です。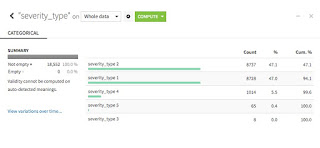
- 複数のモデルを一気に回せる
データの確認、機械学習用のデータセットが完了したら次はモデリングです。従来のPythonやRの場合は一つのモデルに対して一つずつコードを書かなければいけないのですが、Dataikuの場合は組み込み済みモデルがあり、それらを選択でき、一度に回すことができます。もちろん、どの変数を説明変数にするか、変数をどのように追加するか(線形結合・多項式結合)、変数をどのように減らすのか(変数選択)等の設定も可能です。ここのあたりは最近流行りのAutoMLの機能にあたるでしょうか。
各モデルの細かなパラメータチューニングも可能で、値を設定したりすることも可能です。この組み合わせは残すことができ、何回も試行錯誤できる作りになっています。
- RやPythonのコードを組み込むことができる。
準備済みのVisual Recipeやモデルでも物足りないケースが出てくるかと思います。またインポートしたデータセットを使ってEDA(探索的データ分析)を使い慣れた言語(RもしくはPython)で分析したいと思うかもしれません。
そんな人にもJupyter Notebookで分析ができる環境が用意されています。
また、そのままフローに追加することも可能です。また、RMarkdown、Shinyも作成することができます。
* 以下は、Dataiku上のJupyter NotebookでRでggplot2を表示している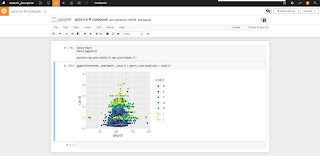
- 関係者との共有がしやすい
これまでの分析結果の共有では、チャートや分析結果をプレゼンテーションにする、Excelでまとめてシェア、最近だとRではRMarkdownでレポート作成等を行っていると思います。Dataikuではそのような別のアプリケーションにデータやチャートを移す必要なく、Dashboardで共有することができます。
あらゆるFunctionからDashboardへPublishすることができ、関連するユーザーはこのDashboardを見ることにより、モデルの結果や分析コメント等を見ることができます。






これ以外でもDeep Learningや、時系列分析、Vishal Recipeを追加できるAdd-onなどの機能が充実しています。
惜しむらくは、まだ日本語へのローカライゼーションができておらず、英語のみ(ツールもWebサイトも)の利用しかできないことでしょうか。
実際に使ってみよう
習うより慣れろ。の言葉通り、実際に触ってみたほうが早いと思います。
フリーエディションをインストールされるもよし、DataikuのWebサイトにはデモとして利用できるページもありますので、それを触ってみてもよし。
実際に利用してみて、Dataikuの良さを実感してみてください。
また、機能が多いため、最初からすべてを一気にできないので、チュートリアルを一つずつやってみて、まずは全体的な流れを覚えていただくのがオススメです。
[フリーエディション]
今後の予定
今後はDataikuを使う際のTipsやナレッジ、Kaggleでのチャレンジなどを載せていく予定です。
0 件のコメント:
コメントを投稿